 JOIN
JOIN
Recommendations on current mechanisms to reserve rights
In the European Union, Article 4 of Directive (EU) 2019/790 on copyright and related rights in the Digital Single Market requires publishers to take active steps to reserve their rights from the text and data mining (TDM) exception for commercial uses. As rightsholders, publishers have the discretion to decide how best to reserve their rights in accordance with the law.
To support its members, STM has developed recommendations for consistent and effective implementation of Article 4. In particular, we supported the development of the TDMRep protocol, a simple solution for signaling content rights through metadata both at platform and work-level across content types.
The methods we point to—robots.txt, TDMRep, and the International Standard Content Code (ISCC)—provide complementary ways for rightsholders to communicate their TDM policies. While none can fully prevent misuse by non-compliant actors, they offer vital transparency signals that strengthen accountability and legal enforceability across the digital ecosystem.
We are constantly monitoring and engaging with stakeholders to consider the emergence of new solutions as well.
However, the lack of transparency and cooperation from some AI companies makes it difficult to verify whether these mechanisms are being respected—the successful implementation of rights reservation is dependent on granular transparency, authorised crawling and penalties for non-compliance.
Quick links

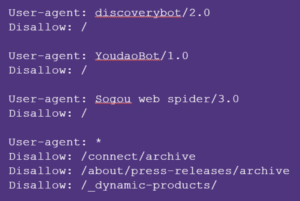
Robots.txt
- A robots.txt file is a plain text document found within a website (example.com/robots.txt), instructing crawlers/bots as to which sections they can access and index from that website;
- It helps website owners to control the behaviour of crawlers and to manage crawling traffic;
- It only covers situations in which the content owner is also the website owner. If content is copied to a website not controlled by the content owner, that indication is lost.
- It is not a standard, rather a widely-used protocol;
- It is a binary mechanism, so it can only instruct a crawler to collect (=0) or not to collect content (=1);
- It provides mere indicators, it doesn’t consist in hard blocking, and a crawler can be programmed to not consult or ignore the instructions;
- It only indicates that content cannot be crawled and does not separate situations in which crawlers are used for multiple purposes, like fetching content for search indexing (which might be allowed) and for training of AI models (which might be disallowed).
- It is the responsibility of the web owner to list all the crawlers that they wish to allow or disallow from their website, thus it risks not being exhaustive and effective and it places a considerable burden on the web owner.
- AIPREF: We are monitoring progress at IETF level to update robots.txt to express AI Preferences.
User-agent: discoverybot/2.0
Disallow: /
User-agent: YoudaoBot/1.0
Disallow: /
User-agent: Sogou web spider/3.0
Disallow: /
User-agent: *
Disallow: /connect/archive
Disallow: /about/press-releases/archive
Disallow: /_dynamic-products/
The Latest AI News from STM
Book, news, and journal publishers join with authors in amicus brief in support of music publishers in Concord v. Anthropic

STM publishes new discussion document on responsible use of research content in generative AI
Global reporting standard for AI disclosure in research: first consultation is open